Getting (g)it: A Case of Cognitive Dissonance
Git has been around for going on 20 years, yet people still continue to write “getting-started” and “common-challenges” tutorials. This is mine.
Like many other people, I have found it difficult to get comfortable
with git. For me, at least, the primary problem was not the confusing
naming of commands (reset, revert, restore; the two uses of
checkout that were almost, but not quite, entirely unlike each
other, neither of which does what checkout seems to imply, and so
on), nor the overwhelming number of individual
“high-level (porcelain)” commands
(although, at over 40 and counting, they do seem to span an entire
alternate universe).
Instead, it was pretty clear to me from the beginning that my difficulties
resulted from a form of cognitive dissonance: what I thought I was
seeing and doing when using git clearly did not entirely match up with
what I was actually seeing and doing. Or maybe it did? I was never
quite sure — and that uncertainty, in regards to things that I
usually take for absolutely granted (such as the integrity of the
fileystems and the reliability of the ls command) panicked and
paralyzed me. One particularly unwelcome (even outright frightening)
manifestation of this was my recurring inability to predict what was
going to happen next: some operation (usually a push) would suddenly
fail, totally unexpectedly. And because I had no mental model why
it should fail, I could not devise a solution to fix the problem, getting
totally, maddeningly stuck. (I am not alone
in this.)
Eventually I was able to trace my difficulties to two main areas of confusion or misconception. Resolving them enough for me to feel comfortable working with git (rather than just following other people’s recipes) required a rather deeper look at git and its operations.
Rather than thinking of git as primarily a version-control system, it is often more appropriate to think of git as both a content-addressable filesystem, and as a unidirectionally traversable object store, with the version-control functionality implemented on top and in terms of those underlying abstractions.
Once these underlying architectural concepts have been accepted and understood, I found git quite easy and intuitive to use.
Illusions, Delusions, and Failures of Perception
There were three separate issues (described and resolved below) where my mental model of git’s actions was incomplete. This is important: if my mental model had been entirely wrong, it would have been easier to correct. But the sense that I was constantly missing part of reality, clearly relevant, but somehow mysteriously invisible, was extremely disorienting — almost uncanny.
- Treat directories of a git repo as materialized views into a separate object store, not as part of the conventional filesystem.
- For every remote branch, git sets up a local proxy (the “remote-tracking branch”), which represents the status of the remote repo on the local system. Do not confuse it with either the local development branch or the actual remote branch.
- Pay attention to what arguments (in particular repo and branch names) git commands silently assume.
1) Now you see it, now you don’t
Using git means that you no longer own your filesystem.
When you change (cd) into a directory of a git repo, you can no
longer trust your filesystem. In fact, at this point, your filesystem
is merely a (materialized) view of a separate object store. That’s
particularly confusing, because this view does live in the regular
filesystem, and its contents can be manipulated with regular filesystem
tools (mv, rm, your favorite editor). Yet the view can also be
changed, at a stroke, by a checking out a different branch or commit.
I think it is helpful to view directories managed by git (that is, local git repos) as no longer being part of the local filesystem, but instead of as living in a separate universe. The artifacts in each working directory are merely projections of the underlying object store into the current workspace.
For someone who is used to viewing “the local disk” as stable, fixed source of truth, that is a major conceptual shift. But at the same time, it is also liberating: I can jumble those files (using tools from the regular, filesystem universe) as much as I want — yet, I can still restore them all (using the tools from the parallel git universe).
Something that I have found exceptionally helpful here is to configure my local shell prompt to include information about the current branch. I have always used a shell prompt that displayed information about the current directory; adding branch information to the prompt therefore felt very natural, and constantly confirms the dual nature of a directory under git: still at the local filesystem path, but also a view into a particular location in the object store.
It is, by the way, not only git checkout or git switch that mess
with the files in my working directory: so do git merge and git rebase (and git bisect). Again: at first sight, this is terrifying:
some tool simply overwrites the files on my disk, leaving obscure
markers everywhere (so that the files won’t even compile anymore). But
that’s ok! It’s just a view! All it takes is the appropriate command
from the parallel universe (git merge --abort or git rebase --abort prior to any commit, or possibly git reset --hard HEAD
otherwise) to safely restore things to where they used to be.
Coming back to branches and commits: there are two additional locations in the object store that can be swapped into the working directory. One is the “staging area” (or the “index”, in a particular unfortunate alternate naming convention for the same thing), and the stack of “stashes”. Conceptionally, they are all more or less the same (namely snapshots); it is unfortunate that they are all manipulated by different commands. (We will come back to working with the staging area below.)
Understanding that a directory under a git repo is merely a view into
the state of the object store has proven tremendously helpful, and
resolved a good chunk of my discomfort with git. But it does leave
me with a different problem: I find it difficult to keep all these
different points in the object store straight. Conceptually: what
lives on branch B? What lives in stash@{2}? I know what the files
are (git will pull them up at a moments notice), but what was the
state of the project and my mental process at that time? What are
the different branches for, and in which state did I leave them in,
the last time I touched them? Commit messages do help, but there
is usually more in my head when working on something than is easily
captured in a commit message — and much more so for
work-in-progress (like a stash).
The contents in the directories of a git repo are merely materialized views into the underlying object store.
2) What you see is not what you think it is
When working with a remote branch, you are working with two.
The real point of git, of course, is working with remote repositories, and git does indeed do a very clever job at that. But it is also where the most frustrating experiences await (again, this is clearly a common sentiment). Strangely, given the importance of interacting with remote repositories, every introduction I have seen makes a total hash of explaining it!
The problem is that when you are dealing with a remote branch, you are in fact dealing with two. Yet no introduction (that I have seen) makes this point sufficiently clearly. Let me give it try.
For each remote development line or “trunk”, there are three branches involved (not just two), and hence there are also three synching problems (instead of two). The branches are as follows:
-
A: The actual remote branch, on the remote repository. You read from this branch using
git fetchorgit pull; you write to it usinggit push. -
B: The “remote-tracking branch”: this is a local, read-only copy of the the remote branch. It acts as a local proxy for the remote branch, allowing you to interact with the remote without network access, or when entirely offline. It is this “remote-tracking branch” that is updated when you run
git fetch(and also bygit pushandgit pull), and caches the state of the remote branch A at the time of the last successful network communication. The name of a “remote-tracking branch” is always of the form<remote>/<branch>, like the ubiquitousorigin/master. As befits a proxy, this “remote-tracking branch” leads a somewhat shadowy existence (for instance, you can’t write to it), and is often somewhat neglected in tutorial presentations.The print version of the git book does not use the term “remote-tracking branch”, instead the book uses the (very confusing) term “remote branch” for this type of branch. However, the online version does use the term “remote-tracking branch."
-
C: The local development branch that is configured to treat the remote branch A as its upstream. This is an entirely regular local development branch, the only difference being that it has been configured to push its updates to the remote branch A. Very often, this configuration happens implicitly: whenever a remote repository is cloned, git will automatically set up a local branch and configure it to treat the remote repository as its upstream. Likewise, when creating a local branch using
checkout -b <branch>and exactly one remote-tracking branch of the same name exists in the local repo, the newly created branch will implicitly be configured to treat the corresponding remote branch as its upstream. Explicit ways to apply this configuration include the-u(or--set-upstream) option ongit push, or the-t(or--track) option when creating a branch usinggit checkout.There is no accepted naming convention for C; it is sometimes called a “tracking branch” (which invariably leads to confusion with B), or an “upstream branch” (which sounds like a description of A).
As there are three branches total, there are also three message flows, as indicated in the following diagram:
git fetchupdates the remote-tracking branch B based on the current state of the remote branch Agit mergeorgit rebaseare used to propagate changes from B to the local development branch Cgit pushpropagates the current state of the local development branch C to the remote A (if successful, a push also updates the local proxy B)
(There is also git pull, which consists of git fetch, immediately
followed by a git merge, or — with the --rebase option —
by a git rebase.)
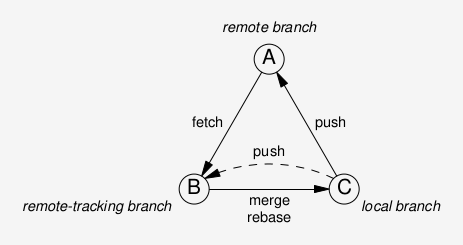
(By the way, this is a diagram that I think I have not seen anywhere else before!)
The important take-away here is that git fetch does not update
the local branch C, instead it updates the “remote-tracking branch” B.
Any changes (commits) that might have occurred on the remote A must
still be transferred from its local proxy B to the actual development
branch C, either via a merge or via a rebase operation. (The git pull
command does bundle these two steps into one command, but it, too,
first updates the local proxy B in the process.)
I think failing to appreciate the interplay between these three
branches, in particular the role (even the existence) of the
“remote-tracking branch” B is a cause for much confusion. Here
is an example: Let’s say I have made some changes (to C). Before
pushing them, I want to grab any changes anybody may have made to
the “master” branch A. Hence I run git fetch, followed by git log
to see what changes need to be merged. The git log shows no new
commits, hence I push — and am totally shocked to see the
push fail. The issue is that git log by itself will show the
changes made to C! To see the remote commits that git fetch
just pulled down, I need to look for changes on B, for example
using git log origin/master or git log origin/master...
Before leaving this topic, I wanted to clarify a bit of terminology.
Because (almost) every repo has an origin, and a master, as well
as an origin/master, it’s easy to get confused:
originis a remote repository (the one that the current local repo was cloned from, in fact)mainormasteris a local development branch (type C)origin/masteris a “remote-tracking branch” (type B)
The push command takes a destination repository and the local
branch to push to the destination, and optionally a different
branch on the remote:
# push <remote> <localbranch>
push origin master
# push <remote> <localbranch>:<remotebranch>
push origin master:testing
Understand the three branches (the remote master, the remote-tracking proxy, and the local working branch) that are involved in non-local workflows, and the information flows between them. In particular, remember that it is the shadowy “remote-tracking branch” that acts as a proxy for the remote repository, not the local working branch.
3) What you think you are doing may not be what you are doing
What you don’t see and didn’t ask for may still confuse you
Not only are there over 40 “high-level” git commands, but each of these commands sports a generous number of arguments and options. Fortunately (or maybe not), many of them have silent defaults: you don’t need to know about the options, git just “does what I mean” (DWIM).
I have found this to be a distinctly mixed blessing. Sure, it’s
nice if I don’t have to supply (say) the name of the remote and
the branch every time I call git push. But does git really
know what I mean? Do I even know myself? (In particular given
situations like the one with the three branches, two real, one
shadow, described above?) I have found that the
pervasive use of implicit, silent defaults has the effect that
I myself don’t know what I am doing — or what I should
be doing at this point. I simply rely on git do “do what I mean”,
and hopefully, git guesses right.
No question, often it does, but definitely not always. In particular
the omission of repo and branch names can have unintended consequences.
How about this (quoted from the
reference for git fetch):
“When no remote is specified, by default the origin remote will be
used, unless there’s an upstream branch configured for the current
branch." Sure, makes sense. But is every user, in particular an
inexperienced one, aware of this? And also aware how the current
branch he or she is on at that moment is configured?
I am not sure what to do about this. Showing the full set of arguments (in tutorials, and so on) would be helpful, to make sure users understand what choices git makes on their behalf. On the other hand, relying on defaults (which, admittedly, very often are reasonable), reduces the cognitive load significantly.
You don’t need to know all the options for all git commands you use on a regular basis, but do make sure you understand what default arguments each command substitutes when called.
Graphs and Head Pointers: Moving Backwards in Time
Given that git is intended as a revision control system, it should
be really easy to restore or revert to previous versions —
but somehow it can all seem very difficult and confusing: do I
use git revert or git restore or git reset? And why do I
need three different commands to begin with?
To answer this question, and to become comfortable with this entire topic, it is necessary to peek a little further under the hood: git organizes its object store in a way that makes total sense to a C programmer, but may not necessarily be meeting naive user expectations. To properly explain what the various commands do, one needs to have some sense for the internal data structures that they manipulate.
Graphs and Pointers
As stated earlier, git acts as an object store. It arranges commits (that is, snapshots) in a DAG (directed, acyclic graph), which is oriented backwards in time: every commit knows its predecessor (or predecessors, in the case of merge commits), but not its successor. Which makes sense, if we want to consider each commit as read-only and frozen once created: if a commit was to contain information about its successors, then it would have to be updated once a successor is created, and hence no longer be frozen. By contrast, a commit’s predecessor is known when the commit is created, and hence each commit can be given a reference to its parent at creation time.
Nevertheless, from a user’s perspective, this can be confusing, because we
tend to think about a project progressing forward in time, rather than
by traversing its ancestry backwards. (It reminds me a little of the
COMEFROM operator of Intercal fame.)
The realization that the commit sequence can only be traversed backwards puts special emphasis on the last, most recent commits on every branch: those are the necessary starting points; without them, the entire branch is (effectively) lost. I say it again: because the sequence of commits can only be traversed backwards, it is absolutely essential to keep references to the most recent commit on each branch; if those pointers are lost, the branch has become inaccessible. (C programmers will feel a certain dread of recognition here.)
The references to these most recent commits on all branches are referred to in the git documentation as the “heads”; in fact, the terms “heads” and “branches” are generally used synonymously. This makes sense, if you think of a “branch” as the commits that are reachable from a given starting point. (It still confuses me, because I tend to think of a branch as a collection of nodes, whereas each head only points to the most recent one of those nodes.) Another way to say this is that the “heads” represent the “tips” of all the branches: the places where new development will usually take place.
- As object store, git organizes its commits or snapshots as a DAG, which is directed backwards in time.
- Branches are identified through their most recent commit, for each branch, its “head” pointer maintains a reference to the most recent commit.
The HEAD Cursor
The HEAD pointer in git maintains information about the “current”
node or commit: essentially, it is a cursor that points to the
location where the next read or write operation will take place.
The commit pointed to by HEAD is usually projected into the
current working directory; a new commit will reference the node
pointed to by HEAD as its parent. It should be emphasized
that HEAD is just an alias, comparable to a symbolic link,
and has no lasting substance. This is in contrast to the
“heads”, which maintain persistent access to the branches
that they point to.
From the foregoing, it should be clear that the HEAD cursor
should usually point to one of the “heads”, thus defining the
“current branch” and the place where the next commit will be
attached. Switching branches means moving the HEAD pointer
from one of the branch tips to another.
But git does not enforce the HEAD pointer to point to one of
the branch tips; it may point to any commit. In fact, that
may be desirable, because it makes it possible to inspect the
state of the project at an arbitrary point in the past: the
command git checkout <commit> will project the state of the
project at the given commit into the working directory, where
the files can be examined.
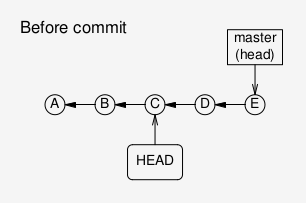
But whenever HEAD points to a commit that is not the most
recent one on a branch, that branch is now in an inconsistent
state; the git documentation refers to it as “headless”. That’s
ok for read-only access, but poses a problem for writes (commits).
If you make a commit in this situation, and then move HEAD
anywhere else, nothing will point to the new commit, and it
will hence be irretrievable. Instead, create a new branch
(really: a branch pointer!) before committing so that there
is a permanent reference to the new commit, even if the HEAD
pointer is moved elsewhere.
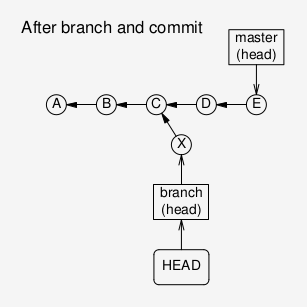
A branch in a “headless” state:
After a commit in a headless state:
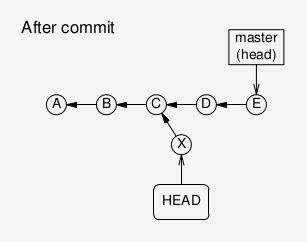
After moving the HEAD pointer away from the new commit.
Nothing points to the new commit X, it is essentially lost.
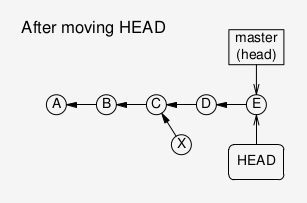
Better: create a new branch (that is: branch pointer), before
committing. Even when HEAD now moves, the new branch pointer
will still point to the new commit.
Pointer Manipulation Commands
Now we can explain what the various pertinent git commands do.
There are several commands that manipulate HEAD and the branch tips
(“heads”): git checkout, git reset, and the new commands
git switch and git restore, as well as git branch. There
is also git revert, which does something quite different,
but serves a related purpose.
git checkout <commit>moves theHEADpointer onlygit reset <commit>moves bothHEADand the branch “head”git branch <branch>creates a new branch head
Confusingly, both git checkout and git reset can take an additional
pathspec argument that describes a file. This changes the behavior of
these commands; we will come back to this.
Old style, common case: git checkout and git reset for commits
The git checkout command essentially moves the HEAD pointer or
cursor around, to change the position where the next read or write
operation will take place. The files in the staging area and the
working directory will be updated accordingly, but changes to the
files in the working directory are not overwritten.
Switching to a
different “branch” means switching to the most recent commit (the
“head” or tip) of that branch. Remember that moving HEAD among
branch heads does no harm, but moving HEAD backwards to an arbitrary
commit (away from the tips), leaves the branch in an inconsistent,
“headless” state. This is fine for read-only access, but any commits
made in this state will be lost. As a convenience, when used with the
-b option, git checkout creates a new branch head and moves HEAD
to it in a single step.
By contrast, git reset <commit> moves both HEAD and the branch
pointer itself, leaving the branch in a different, but consistent
state. This can be used to get rid of old commits. Imagine we move
both HEAD and the branch pointer back by two commits, using
git reset HEAD~2. Now the two most recent commits dangle: nothing
refers to them anymore, they are (essentially) unreachable and will
be reaped the next time git’s garbage collector runs. It is as if
these commits had never happened. In a local repo that’s exactly
what we want to achieve; but if those commits had been pushed to a
public repo, their sudden disappearance will cause problems.
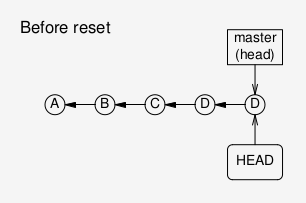
Before git reset: both HEAD and the branch “head” point to the
most recent commit D.
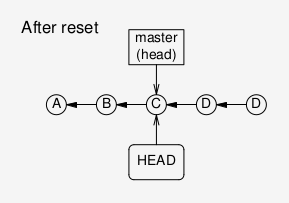
After git reset HEAD~2: now both HEAD and the branch “head” point
to a previous commit; the branch is in a consistent state.
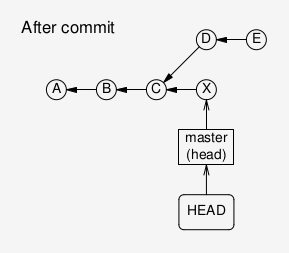
When creating a new commit X in this situation, both HEAD and
the branch “head” will point to the new commit, so that the branch
is in a consistent state. However, nothing points to the two previous
commits (D and E) anymore, they are now inaccessible and essentially
lost.
The git reset command takes three options (--soft, --mixed,
and --hard, with --mixed being the default option) that control
how the working directory and the staging area are updated:
--soft: neither staging area nor working directory are updated--mixed: the specified commit is projected into the staging area, but the working directory is not updated--hard: the specified commit is projected into both the staging area and the working directory
To get rid of the last commit and to reset the working directory to
the its state prior to that commit, use git reset --hard HEAD^.
Be aware that this will clobber any edits in the working directory.
Also, don’t do this if the commit has already been shared with others
(that is, been pushed to a remote).
With a pathspec
When called with a pathspec in addition to the commit identifier,
both git checkout and git reset change their behavior: they
retrieve the specified file and project it into either the staging
area or the working directory, but they do not move any pointers
around.
git checkout <commit> <file>retrieves the version of the file from the specified commit and projects it into the working directory, clobbering the current contents of the directorygit reset <commit> <file>updates the staging area with the version of the file from the specified commit
Two common example applications:
# Overwrite any changes to file.txt with the most recent commit:
git checkout HEAD file.txt
# Equivalent:
git checkout -- file.txt
# Unstage file.txt:
git reset HEAD file.txt
The command git reset HEAD <file> puts the last committed version of
that file into the staging area. Since now there is no change between
staging and HEAD, the file has (for all practical purposes) been
“unstaged”: there are no changes to be committed.
Finally, there are no --hard and --soft options when using git reset
with a pathspec.
New style: git switch and git restore
The naming and the dual modes (file and commit) of git checkout
and git reset have long been recognized as problems. In response
to this, two new commands were added to git relatively recently
(in 2019).
git switch <branch>will setHEADto the tip of the specified branch. In addition, the staging area and the working directory will be updated accordingly. Using the-coption, the command will create a branch (a new “head”) and switchHEADto it in a single step. (This command is a replacement for the commit-level operation ofgit checkout.)git restoreis a replacement for the file-level variants ofgit checkoutandgit reset. It does not move pointers, but restores individual files to the working directory (or to the staging area).
A few commented examples may be most helpful in illustrating the
behavior and typical usage of git restore:
# Restore copy of file in working dir to previous commit:
git restore <file>
# Restore copy of file in working dir to a specific commit:
git restore --s <commit> <file>
# Restore the version of the file in the staging area to the
# last commit (effectively unstaging it):
git restore --staged <file>
Danger, Danger!
Both git checkout with a pathspec and git reset with the --hard
option will potentially overwrite uncommitted changes in the working
directory. This leads to the uncommon scenario that git is making
changes in the “conventional” filesystem that git itself cannot
undo. For this reason, the git documentation is careful to point out
their consequences.
The git checkout command in particular can be seen as having a
“dangerous” version (with a pathspec) and a “safe” one (without).
It has been said that git switch replaces the “safe” half of
the git checkout command, and that git restore replaces the
“unsafe” version.
Fixing public commits: git revert
The last command that is relevant in the context of “undoing things”
is git revert. It is structurally different than the ones discussed
so far, because it does not move pointers around, but creates a new
commit.
The git revert <commit> command takes a commit identifier, and
then creates a new commit, at the position pointed to by HEAD,
so that the content of the repo now matches the specified commit.
Essentially, the command creates and applies a “patch” that reverts
the changes made since the specified commit.
Because this command does not discard any commits, it is safe to
use on public repos.
Summary and Resources
The two tables below try to summarize the commands described, and their
effect on the HEAD pointer, the “head” pointers to the branch tips,
and the effect the commands have on the staging area and the working
directory. (Empty entries indicate no effect.)
Commit-Level Invocation (Without pathspec):
| Command | Unit | HEAD | Tip | Staging | Workdir |
|---|---|---|---|---|---|
git branch <branch> |
Create | ||||
git switch <branch> |
Move | Update | Update | ||
git switch -c <branch> |
Move | Create | Update | Update | |
git checkout <commit> |
commit | Move | Update | Update | |
git checkout <branch> |
commit | Move | Update | Update | |
git checkout -b <branch> |
commit | Move | Create | Update | Update |
git reset --soft <commit> |
commit | Move | Move | ||
git reset <commit> |
commit | Move | Move | Update | |
git reset --hard <commit> |
commit | Move | Move | Update | Clobber uncommitted |
File-Level Invocation (With pathspec):
| Command | Unit | HEAD | Tip | Staging | Workdir |
|---|---|---|---|---|---|
git checkout <commit> <file> |
file | Update | Clobber uncommitted | ||
git reset <commit> <file> |
file | Update | |||
git restore <file> |
file | Update | |||
git restore --staged <file> |
file | Update |
Helpful resources on the topics and commands discussed in this section include:
- Resetting, checking out and reverting and git reset on the Atlassian website
- Undoing things and Reset demystified in the git book
Merging, Rebasing, and Remote Workflows
With all the pieces in place, we can now give a complete walkthrough through the steps required for an idealized, clean workflow based on pushes to a remote — without unexpected (and unwelcome) hangups! The main point is to properly choreograph the flow of information among the three branches involved.
Working with remotes always involves some form of merge-like activity: simply because changes from one repo must be incorporated into another one. Even though branches in different repos may track each other, they are still physically and logically distinct.
One (minor) conceptual problem here is that in a typical open-source development situation one developer (or maintainer) pulls changes from another repo, and incorporates them into the local one. Hence git’s emphasis on multiple remotes, with none necessarily being singled out (“origin is not special”). But in a corporate situation, git tends to be used much more in a client/server model, with a central, normative repository that developers push to. This seems to be the source of some of the frustrations with git in practice.
In such a situation, with a central repository that people push to, the local remote-tracking branch is updated from the central repo, then updates from the remote-tracking branch B need to be carried over to the local development branch C (either via a merge or via a rebase), and the new work done on C must be integrated with the remote branch A. When attempting to push to a remote, the main concern is to be up-to-date with the remote before the push, since it is not really possible to resolve merge-conflicts on a remote. All integration has to be done locally, before the push.
The primary workflow therefore goes like this:
- Update the “remote-tracking branch” B from the remote A.
- Carry updates over from B to the local development branch C, resolving any conflicts in the process.
- Push the new state of C to the remote A. If the push succeeds, git will also update B to reflect the new state of A.
Assuming the simplest possible case, with a single remote (origin),
and a single remote branch (feature), the commands might be:
# Fetch all info from remote; this updates the remote-tracking branch
git fetch
# Examine changes from the remote branch via the remote-tracking branch
git log origin/feature
This fetches any updates from the remote, and updates the “remote-tracking
branch” B, but does not make any further changes. To see what has changed
on the remote, it is necessary to specify the name of the remote-tracking
branch B to git log — by default, git log will only show the
changes on the local development branch C!
Now, assuming I made no commits to my local branch yet (for instance, at the beginning of a workday), I can pull any remote changes into my local branch C. This brings the local branch up-to-date with the remote.
# Fetch changes from remote and merge them into local branch
git pull
On the other hand, if I already made commits to the local branch, then I want to pull in those changes, but ahead (that is: earlier) than my local changes.
# Rebase local development branch on top of the remote state
git rebase origin/feature
This will append my local commits to the most recent version of the remote branch: the recent commits on my local branch (after it diverged from the remote) are “rebased” onto the current state of the remote branch.
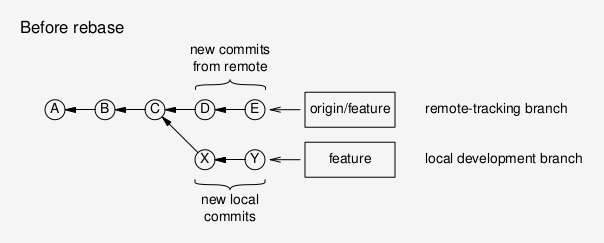
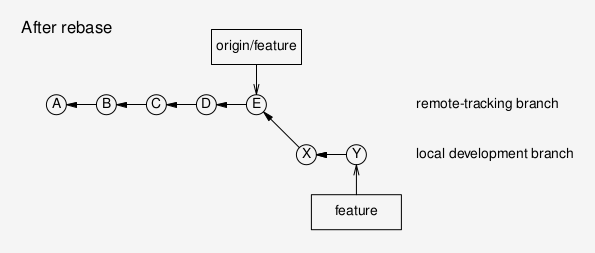
Now I can push my changes to the remote, and they will simply be tacked on at the end, in what is called a “fast-forward merge”, because all possible conflicts have been resolved in the local rebase process.
# Push the changes from local branch to remote; update remote-tracking branch
git push
(The term “fast-forward merge” is always made to sound weird, but all it means is that no commits occurred on the destination branch since you diverged from it. In this case the “merge” amounts simply to tacking on your commits to the end of the destination branch.)
The workflow and the situation described here are clearly the simplest possible case, but it can serve as a baseline, for more complex situations. Many different workflow and branching models have been discussed, mostly in regards to the application of git in situations around a central repository.
Discussions of git workflows and branching strategies are plentiful. The following ones I have found helpful, because they get into concrete steps and commands, not just big-picture issues:
-
A better git workflow with rebase : short and to the point
-
Git workflow : this is longer and discusses alternatives
-
Git-workflow vs feature branching : this provides a lot of detailed explanation and rationale
I do not want to enter the whole merge-vs-rebase debate, but here
are some pointers on git rebase:
-
Rebasing in the git book
-
git rebase and merging vs rebasing on the Atlassian website
-
The git rebase handbook : a definitive guide
Patches and Differences
When examining the history of a branch, it is often useful to see
what has changed in each commit. This can be done using the -p
option to git log. The git add and git stash commands also
accept a -p option, to add or stash only specific changes (hunks).
The git diff command can show differences between different
locations in the object store.
| Command | Description | Usage |
|---|---|---|
git diff --cached |
Difference between HEAD and staging area |
What would be committed by commit now |
git diff |
Difference between the staging area and the working directory | Changes would not be included by commit now |
git diff HEAD |
Difference between HEAD and working directory |
What would be committed commit -a now |
The command git status shows a brief summary of this. In particular,
git status does not show the contents of the staging area, but how
it differs from the last commit and the working directory.
Tools
If one regards git as primarily an object store, with a complex inner state and managing multiple objects and storage locations, then it would be desirable to have a tool that provided an at-a-glance overview of everything relevant. Of course there is nothing wrong with the command line tools, but they only show updates when run explicitly (and frequently, one needs to run multiple tools to see everything). Wouldn’t it be nice to have a dashboard that keeps me informed about and ahead of what’s happening in the object store?
I have found that GUI tools tend to focus too much on branch flows and explicit diffs: that’s nice, but more the purview of a “diff and merge tool”, than of an object store frontend.
I have already mentioned that I have found a git-aware shell prompt to be most helpful, as a reminder of now only the current working directory, but also the current branch — this being the alternate location that the git parallel filesystem imposes.
Two more comprehensive, text-based frontends that I have found helpful are:
- lazygit standalone tool (The author’s Lazygit Turns 5 essay is also interesting.)
- magit for Emacs
Resources
General References
-
Pro Git The git book, fully available online as well as in print. Very good, but not very conceptual.
-
Learn Git A series of tutorials and individual posts on git, by Atlassian. The best overall documentation on git that I have found on the Web.
-
Git User Manual The official git user manual. Concise and comprehensive, but more suitable as a recap for an established user than as a first introduction.
Battling Confusion
Other people have been confused by git and tried to provide explanations. The following two have been most helpful (and provided inspiration for the present write-up):
Other Resources
Other online resources that I have found interesting or valuable: